UMass systems lunch
The UMass CS Systems Lunch talk series (currently organized by Prashant Shenoy and Mohammad Hajiesmaili) is back in person! All talks are Fridays at 12:00pm Eastern in room A215
(LGRC) Everyone interested in systems is welcome to attend. Systems Lunch is a great opportunity to
hear exciting talks by visitors as well as to learn about projects
going on in the College.
Fall 2024 - Spring 2025
- October 4, 2024: Ali Begen (Ozyegin University): Unifying Real-Time Communications and Content Delivery with Media-over-QUIC Transport
- October 18, 2024: Nico Christianson (Caltech): End-to-end learning for reliable decision-making in energy and sustainability
- October TBD, 2024: Pengfei Su (UC Merced): TBD
Fall 2022 - Spring 2023
- May 5, 2023: Malte Schwarzkopf (Brown): Privacy Compliance as a First-Class System Design Principle
- February 10, 2023: Adam Belay (MIT): Achieving Microsecond-scale Resource Fungibility with Nu
- October 7, 2022: Lorenzo Alvisi (Cornell): Orderrr! A tale of Money, Intrigue, and Specifications
- November 4, 2022: Ulfar Erlingsson (LaceWork): The New Normal: Achieving Security in an Ever-Changing Cloud
November 18, 2022: Christina Delimitrou (MIT): Designing the Next Generation Cloud Systems: An ML-Driven Approach (to be rescheduled)December 2, 2022: Abhishek Bhattacharjee (Yale): TBD (to be rescheduled)- December 9, 2022: Elena Glassman (Harvard): TBD
Fall 2020 - Spring 2021
October 2, 2020
| Adrian Sampson (Cornell) |
| Languages and Compilers for Accelerator Design |
 |
| We need to make it easier to design custom accelerators, especially for reconfigurable hardware (i.e., FPGAs). The current mainstream options are hardware description languages (HDLs), which are low-level languages that make it feel like you’re wiring up a circuit by hand, and high-level synthesis (HLS) tools, which compile legacy software languages like C or C++ to an HDL. The thesis of this talk is that better alternatives are possible. We find empirically (and unsurprisingly) that the semantic chasm between C++ and hardware circuits comes with myriad correctness and performance pitfalls. We advocate instead for more research on accelerator design languages: programming models that maintain computational semantics while not attempting to shield developers from thinking about hardware. Our lab is designing a programming language, Dahlia, that uses a type system to restrict HLS programs to a subset with predictable semantics and performance. Beyond Dahlia, we are designing an open-source compiler infrastructure to support the construction of new accelerator design languages. |
| Bio: Adrian Sampson is an assistant professor in the computer science department at Cornell. He works on programming languages, computer architecture, and the abstractions that separate them. He previously worked on approximate computing, the idea that we should allow machines to expose errors to some kinds of applications as a trade-off for computational efficiency. He sees approximate computing as an instance of a broader breakdown of airtight distinctions between hardware and software concerns. |
October 9, 2020
| Hila Peleg (UCSD) |
| Programmer Tools with Program Synthesis |
 |
| Program synthesis is the problem of generating a program to satisfy a specification of user intent. Since these specifications are usually partial, this means searching a space of candidate programs for one that exhibits the desired behavior. A lion’s share of the work on program synthesis focuses on new ways to perform the search, but allowing the user to communicate intent remains a major challenge. Synthesis tools are often designed either with no particular group of users in mind, or for domain-specific users such as Excel users or data scientists. We wish to leverage synthesis to create better tools for developers, which means we should narrow our focus and our understanding of our users. Focusing on any subgroup of users allows making assumptions on both the input the user can generate for the synthesizer and the output they can consume. In the case of developers, concepts that are part of the programmer’s life such as code review and read-eval-print loops (REPL) can be leveraged for interactions with a synthesizer. This talk describes two synthesis-based tools that both leverage and cater to programmers as their users. However, designing for the user can put the interface of the synthesizer at odds with state of the art synthesis techniques. Synthesis is, at best, a computationally hard problem, and many existing program synthesis tools and techniques were designed around the synthesizer and its internals, their the user interface dictated by the needs of the synthesizer. We therefore demonstrate the process of concurrently building both the synthesizer and its intended user-facing tool as a solution to this problem. |
| Bio: Hila Peleg is a postdoctoral researcher in the CSE Department at University of California, San Diego, advised by Nadia Polikarpova. She recieved her PhD at the Technion, Israel. She also holds a degree in literature. Her research explores the way program synthesis can be transformed into tools for developers. |
October 16, 2020
| Jonathan Ragan-Kelley (MIT) |
| Organizing Computation for High-Performance Graphics and Visual Computing |
 |
| In the face of declining returns to Moore’s law, future visual computing applications—from photorealistic real-time rendering, to 4D light field cameras, to pervasive sensing with deep learning—still demand orders of magnitude more computation than we currently have. From data centers to mobile devices, performance and energy scaling is limited by locality (the distance over which data has to move, e.g., from nearby caches, far away main memory, or across networks) and parallelism. Because of this, I argue that we should think of the performance and efficiency of an application as determined not just by the algorithm and the hardware on which it runs, but critically also by the organization of its computations and data. For algorithms with the same complexity—even the exact same set of arithmetic operations—the order and granularity of execution and placement of data can easily change performance by an order of magnitude because of locality and parallelism. To extract the full potential of our machines, we must treat the organization of computation as a first-class concern, while working across all levels, from algorithms and data structures, to programming languages, to hardware. |
| This talk will present facets of this philosophy in systems I have built for image processing, 3D graphics, and machine learning. I will show that, for the data-parallel pipelines common in these data-intensive applications, the possible organizations of computations and data, and the effect they have on performance, are driven by the fundamental dependencies in a given problem. Then I will show how, by exploiting domain knowledge to define structured spaces of possible organizations and dependencies, we can enable radically simpler high-performance programs, smarter compilers, and more efficient hardware. Finally, I will show how we use these structured spaces to unlock the power of machine learning for optimizing systems. |
| Bio: Jonathan Ragan-Kelley is Esther and Harold E. Edgerton Assistant Professor of Electrical Engineering & Computer Science at MIT, and Assistant Professor of Electrical Engineering & Computer Science at UC Berkeley. He was previously a postdoc in computer science at Stanford, where he worked with Pat Hanrahan, and spent a year as a visiting researcher at Google. His work focuses on high-efficiency computer graphics, at the intersection of graphics with systems, architecture, and compilers. He did his PhD with Frédo Durand and Saman Amarasinghe at MIT CSAIL, developing the Halide language together with Andrew Adams, has worked at three major GPU vendors in architecture, compilers, and research, and built a real-time preview system for the special effects industry in collaboration with Industrial Light & Magic. |
October 23, 2020
| Mike Hicks (Maryland) |
| A Verified Optimizer for Quantum Circuits |
 |
| (No specific background on quantum computing will be needed to understand this talk.) |
| Programming quantum computers will be challenging, at least in the near term. Qubits will be scarce, and gate pipelines will need to be short to prevent decoherence. Fortunately, optimizing compilers can transform a source algorithm to work with fewer resources. Unfortunately, the very factors that motivate optimizing quantum compilers make it difficult to test their correctness. Formal methods can help. I will present VOQC, the first fully verified compiler for quantum circuits, written using the Coq proof assistant. Quantum circuits are expressed as programs in a simple, low-level language called SQIR, which is deeply embedded in Coq. Optimizations and other transformations are expressed as Coq functions, which are proved correct with respect to a semantics of SQIR programs. SQIR uses a semantics of matrices of complex numbers, which is the standard for quantum computation, but treats matrices symbolically in order to reason about programs that use an arbitrary number of quantum bits. SQIR’s careful design and our provided automation make it easy to write and verify a broad range of optimizations in VOQC, and even allow us to verify correctness properties of interesting source SQIR programs. This is joint work with Kesha Hietala, Robert Rand, Shih-Han Hung, Xiaodi Wu, and Michael Hicks, all at UMD. |
| Bio: Michael W. Hicks is a Professor in the Computer Science Department at the University of Maryland, where he has been since 2002, and the CTO of Correct Computation, Inc. (CCI), a role he has held since late 2018. His research interests range over topics in programming languages, computer security, systems, and software engineering. He was the first Director of the University of Maryland’s Cybersecurity Center (MC2), and was the elected Chair of ACM SIGPLAN, the Special Interest Group on Programming Languages; he now edits its blog, PL Perspectives, at https://blog.sigplan.org. In ongoing projects he is collaborating with the Checked C project to develop techniques for securing legacy C code; exploring synergies between cryptography and programming languages; developing techniques for better random (fuzz) testing and probabilistic reasoning; and designing high-assurance tools and languages for quantum computing. |
October 30, 2020
| James Mickens (Harvard) |
| Oblique: Accelerating Page Loads Using Symbolic Execution |
 |
| Mobile devices are often stuck behind high-latency links. Unfortunately for mobile browsers, latency (not bandwidth) is often the key influence on page load time. Proxy-based web accelerators hide last-mile latency by analyzing a page’s content, and informing clients about useful objects to prefetch. However, most accelerators require content providers to divulge cleartext HTTPS data to third-party analysis servers. Acceleration systems can be installed on first-party web servers, avoiding the violation of end-to-end TLS security; however, due to the administrative overhead (and additional VM costs) associated with running an accelerator, many first-party content providers would prefer to outsource the acceleration work—if outsourcing were secure. In this talk, I introduce Oblique, a third-party web accelerator which enables secure outsourcing of page analysis. Oblique symbolically executes the client-side of a page load, generating a prefetch list of symbolic URLs. Each symbolic URL describes a URL that a client browser would fetch, given user-specific values for cookies, the User-Agent string, and other sensitive variables. Those sensitive values are never revealed to Oblique’s analysis server. Instead, during a real page load, the user’s browser concretizes URLs by reading sensitive local state; the browser can then prefetch the associated objects. Experiments involving real sites demonstrate that Oblique preserves TLS integrity while providing better performance than state-of-the-art accelerators. For popular sites, Oblique is also financially cheaper in terms of VM costs. |
| Bio: James Mickens is a professor of computer science at Harvard University. In the modern era, he spends most of his time trying to avoid unnecessary Zoom meetings. In the pre-modern era, he spent most of his time trying to avoid unnecessary in-person meetings. James Mickens’ spirit animal is a Pokemon that cannot attend meetings. Society will eventually realize his genius and give him a Nobel Peace Prize. James Mickens will not attend the award meeting. |
November 13, 2020
| Tianqi Chen (CMU) |
| TVM: An automated deep learning compiler |
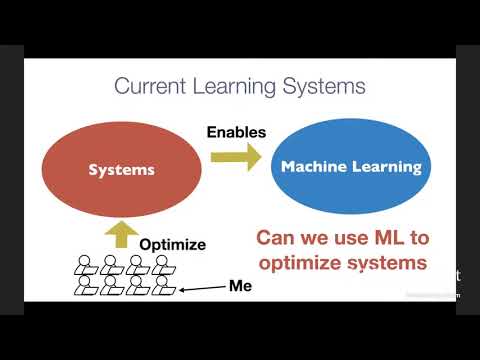 |
| Data, models, and computing are the three pillars that enable machine learning to solve real-world problems at scale. Making progress on these three domains requires not only disruptive algorithmic advances but also systems innovations that can continue to squeeze more efficiency out of modern hardware. Learning systems are in the center of every intelligent application nowadays. However, the ever-growing demand for applications and hardware specialization creates a huge engineering burden for these systems, most of which rely on heuristics or manual optimization. In this talk, I will present a new approach that uses machine learning to automate system optimizations. I will describe our approach in the context of deep learning deployment problems. I will first discuss how to design invariant representations that can lead to transferable statistical cost models, and apply these representations to optimize tensor programs used in deep learning applications. I will then describe the system improvements we made to enable diverse hardware backends. TVM, our end-to-end system, delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned deep learning frameworks. |
| Bio: Tianqi Chen is currently an Assistant Professor at the Machine Learning Department and Computer Science Department of Carnegie Mellon University. He received his PhD. from the Paul G. Allen School of Computer Science & Engineering at the University of Washington, working with Carlos Guestrin on the intersection of machine learning and systems. He has created three major learning systems that are widely adopted: XGBoost, TVM, and MXNet (co-creator). |
November 20, 2020
| Emin Gün Sirer, Cornell / Ava Labs |
| Open and Programmable Finance with Avalanche |
 |
| Avalanche is an open-source platform for launching decentralized applications and enterprise blockchain deployments in one interoperable, highly-scalable ecosystem. This talk will focus on the Avalanche network and the potential for decentralized and institutional finance applications built upon it. |
| Bio: Emin Gun Sirer is a professor of computer science at Cornell University, founder of Ava Labs, co-founder of bloXroute Inc, and co-director of the Initiative for Cryptocurrencies and Smart Contracts (IC3). Among other things, Sirer is known for having implemented the first currency that used proof of work to mint coins, for selfish mining, for characterizing the scale and centralization of existing cryptocurrencies, as well as having proposed the leading protocols for on-chain and off-chain scaling. Of all his collaborations, he is proudest of his contributions to the John Oliver Show’s segment on cryptocurrencies. |
February 12, 2021
| Işıl Dillig, University of Texas at Austin |
| Computer-Aided Programming Across the Software Stack |
| Program synthesis techniques aim to generate executable programs from expressions of user intent. This talk will showcase various applications of program synthesis across different layers of the software stack, starting from computer end-users to application programmers and all the way down to systems programmers. It will also highlight the usefulness of program synthesis for addressing different software concerns, including functionality, correctness, performance, and security. |
| Bio: Işıl Dillig is an Associate Professor of Computer Science at the University of Texas at Austin where she leads the UToPiA research group. Her main research area is programming languages, with a specific emphasis on program synthesis and static analysis. The techniques developed by her group aim to make software systems more reliable, secure, and easier to build in a robust way. Dr. Dillig is a Sloan Fellow and a recipient of the NSF CAREER award. She obtained all her degrees (BS, MS, and PhD) from Stanford University. |
February 19, 2021
| Emina Torlak, University of Washington |
| Solver-Aided Programming for All |
| Solver-aided tools have automated the verification and synthesis of practical programs in many domains, from high-performance computing to executable biology. These tools work by reducing verification and synthesis tasks to satisfiability queries, which involves compiling programs to logical constraints. Developing an effective symbolic compiler is challenging, however, and until recently, it took years of expert work to create a solver-aided tool for a new domain. In this talk, I will present Rosette, a programming language for rapid creation of solver-aided tools. To build a new tool, you write an interpreter for the tool’s input language, and Rosette lifts this interpreter into a symbolic compiler. This is made possible by Rosette’s symbolic virtual machine, which can translate both a language implementation and programs in that language to efficient constraints. Since its first public release in 2014, Rosette has enabled a wide range of programmers, from professional developers to high school students, to create over 30 new verification and synthesis tools. Example applications include verifying radiation therapy software in current clinical use, synthesizing GPU kernels, and verifying and synthesizing just-in-time compilers that are part of the Linux operating system. This talk will provide a brief introduction to Rosette and describe a few recent applications. |
| Bio: Emina Torlak is an Associate Professor at the University of Washington, working at the intersection of programming languages, formal methods, and software engineering. She is the creator of the Kodkod constraint solver, which has been used in over 70 academic and industrial tools for software engineering, and Rosette, a new language that makes it easy to create efficient tools for program verification, synthesis, and more. |
Previous systems lunch talks
Fall 2019
Fall 2017 - Spring 2018
Fall 2016
- September 30, 2016: Joe Gibbs Politz (UCSD) and Ben Lerner (Northeastern): Pyret: Language Design for #CS4All
- October 3, 2016: Harry Xu (UC-Irvine): Marrying Generational GC and Region Techniques for High-Throughput, Low-Latency Big Data Management
- October 24, 2016: Tim Kraska (Brown): Interactive Data Science
- November 7, 2016: Gilles Muller (INRIA): Safe multicore scheduling in a Linux cluster environment
- December 13, 2016: Reza Shokri (Cornell): Membership Inference and Privacy in Machine Learning
Fall 2015
- September 28, 2015: Don Porter (Stony Brook): BetrFS: Write-Optimization in a Kernel File System
- October 19, 2015: Remco Chang (Tufts): Big Data Visual Analytics: A User-Centric Approach
- November 2, 2015: Ethan Heilman (Boston University): Eclipse Attacks on Bitcoin’s Peer-to-Peer Network
Fall 2014 - Spring 2015
- September 22, 2014: Guy Fedorkow (Juniper Networks): High-Scale Routers for Internet Infrastructure
- September 26, 2014: Mike Swift (Wisconsin): New Interfaces to Storage-Class Memory
- October 20, 2014: Jan Vitek (Northeastern): The Case for the Three R’s of Systems Research: Repeatability, Reproducibility and Rigor
- October 27, 2014: Greg Morrisett (Harvard): Formalizing the x86
- November 3, 2014: Armando Solar-Lezama (MIT): Constraint based synthesis beyond automated programming
- November 17, 2014: Tony Printezis (Twitter): Use of the JVM at Twitter: a Bird’s Eye View
- November 25, 2014: Anindya Banerjee (IMDEA/NSF): Modular Reasoning for Behavior-Preserving Data Structure Refactorings
- December 8, 2014: Jean Yang (MIT): A Language for Automatically Enforcing Information Flow Policies
- April 27, 2015: Bryan Ford (EPFL): Warding off timing attacks in Deterland
Fall 2013 - Spring 2014
- September 23, 2013: Niko Matsakis (Mozilla Research): Guaranteeing Memory Safety in Rust
- September 30, 2013: Arjun Guha (UMass): Programming Languages meets Programmable Networks
- October 21, 2013: Veselin Raychev (ETH-Zurich): EventRacer: Finding Concurrency Errors in Web Sites
- November 4, 2013: Nenad Medvidović (USC): Architectural Decay in Software Systems: Symptoms, Causes, and Remedies
- February 10, 2014: Claire Le Goues (CMU): Automatic Program Repair Using Genetic Programming
- May 12, 2014: Milind Kulkarni (Purdue): Automatically enhancing locality in irregular applications
Fall 2012 - Spring 2013
- September 17, 2012: Alexandra Meliou (UMass): Reverse Engineering Data Transformations
- October 1, 2012: Ben Shneiderman (Maryland): Information Visualization for Medical Informatics
- December 10, 2012: Kevin Walsh (Holy Cross): Authorization and Trust: Lessons from the Nexus Project
- April 8, 2013: Rick Hudson (Intel): River Trail: Adding Data Parallelism to JavaScript
- April 22, 2013: Ramesh Sitaraman (UMass): The Billion Dollar Question in Online Videos: How Video Performance Impacts Viewer Behavior?
- April 29, 2013: Robert Grimm (NYU): SuperC: Parsing All of C by Taming the Preprocessor
Fall 2011 - Spring 2012
- September 15, 2011: Jeff Chase (Duke): Trust in the Federation: Authorization for Multi-Domain Clouds
- September 19, 2011: Christophe Diot and Renata Teixeira (Technicolor / CNRS and UPMC Sorbonne Universités): Challenges in digital services delivery / Performance of Networked Applications
- October 3, 2011: Peter Sweeney (IBM TJ Watson): The State of Experimental Evaluation of Software and Systems in Computer Science
- November 7, 2011: Sriram Rao (Yahoo! Research): I-files: Handling Intermediate Data In Parallel Dataflow Graphs
- November 21, 2011: Gene Cooperman (Northeastern): Temporal Debugging via Flexible Checkpointing: Changing the Cost Model
- November 22, 2011: Ben Livshits (Microsoft Research): Finding Malware on a Web Scale
- February 13, 2012: Stephen Freund (Williams): Cooperative Concurrency for a Multicore World
Fall 2010 - Spring 2011
- October 25, 2010: Saman Amarasinghe (MIT): PetaBricks: A Language and Compiler Based on Autotuning
- November 8, 2010: Daniel Jiménez (UTSA): Reducing Wasted Speculation
- February 28, 2011: Simha Sethumadhavan (Columbia): Trustworthy Hardware from Untrustworthy Components
- March 28, 2011: Angelina Lee (MIT): Using Thread-Local Memory Mapping to Support Cactus Stacks in Work-Stealing Runtime Systems
- April 27, 2011: Dan Grossman (Washington): Collaborating at the Hardware/Software Interface: A Programming-Languages Professor’s View
Fall 2009 - Spring 2010
- September 29, 2009: Stephen Freund (Williams): FastTrack: Efficient and Precise Dynamic Race Detection
- October 6, 2009: Sam Guyer (Tufts): Virtual Machine Introspection for Program Understanding and Debugging
- October 13, 2009: Eran Yahav (IBM): Software Reliability: Untold Stories of Synthesis, Verification and Runtime Checking
- October 20, 2009: Geoffrey Werner Challen (Harvard)
- November 3, 2009: Ben Livshits (Microsoft Research): Towards Better Performance and Security for AJAX Web Applications
- November 17, 2009: Mike Swift (Wisconsin): Software Support for Improved Driver Reliability
- November 24, 2009: Bill Hesse (Google): Compiling JavaScript to Fast Executable Code
- December 1, 2009: Michael Scott (Rochester): Transactional Memory, Six(teen) Years In
- January 26, 2010: Martin Rinard (MIT): Automatically Reducing Energy Consumption, Improving Performance and Tolerating Failures with Good Quality of Service
- February 1, 2010: Allen Malony (Oregon): Extreme Performance Engineering: Petascale and Heterogeneous Systems
- March 2, 2010: Martin Hirzel (IBM): Programming Language Challenges and Solutions in Stream Processing
- March 10, 2010: Kim Hazelwood (UVa): A Case for Runtime Adaptation Using Cross-Layer Approaches
- March 30, 2010: Vitaliy Lvin (Google): SPDY, a new application-layer protocol for a faster Web
- April 6, 2010: Stefan Leue (Konstanz)
- April 13, 2010: Barath Raghavan (Williams): Overloading the Internet with Decongestion Control
- May 4, 2010: Philippe Cudré-Mauroux (MIT): SciDB: A Science-Oriented Database Management System
Spring 2007
- February 27, 2007: Stephen Freund (Williams): Velodrome
- March 5, 2007: Brian Taylor: PhotoBase - A Test Tube for Collaborative Sensing Experiments
- March 12, 2007: Bruno Ribeiro
- March 26, 2007:
- Aruna Balasubrmanian: Web search on buses
- Daniel Menasche, Guto Rocha, Sookhyun Yang, and Bin Li: Bundling builds robustness in BitTorrent
- April 2, 2007: Emmanuel Cecchet (EPFL): Middleware-based Database Replication: The Gaps between Theory and Practice
- April 16, 2007:
- Bin Chen: Applying Finite-State Verification to Complex Medical Processes
- Matt Marzilli: Process-Driven GUIs
- April 30, 2007: Ben Ransford: Pacemakers and Implantable Cardiac Defibrillators: Software Radio Attacks and Zero-Power Defenses